[羅戈導讀]希望物流行業(yè)越來越多人能認識到大數據與AI的本質,不去做看皇帝新裝的看客。
[羅戈導讀]希望物流行業(yè)越來越多人能認識到大數據與AI的本質,不去做看皇帝新裝的看客。


近日關注到某通物流新成立分公司招聘數據工程師,招聘要求如下:
任職要求:
精通HiveSQL,有較豐富的HiveSQL性能調優(yōu)經驗
優(yōu)秀的分析問題和解決問題的能力,對解決具有挑戰(zhàn)性問題充滿激情
熟悉至少一項分布式計算平臺,例如Hadoop,Spark,Hive,Storm,Kafka等
至少熟練使用Shell、Python、Perl等腳本語言之一
了解數據倉庫建設基本思路,有數據倉庫建設項目經驗
結合這樣的招聘要求,今天我想以自身多年的系統(tǒng)開發(fā)及產品管理經驗,給大家分享一些心得,希望對大家有所有幫助。
一個誤區(qū):業(yè)務在線化尚未實現,已經在談大數據及AI
首先,我們來看看大數據的含義:大數據是指數據量級大到現有的軟硬件無法從中獲取“合理的、科學的、或者有意義的知識”。一般常用的處理工具是Hadoop,Spark。
其次,人工智能(Artificial Intelligence),英文縮寫為AI。簡單的理解就是用計算機程序從已有的大量數據中計算出需要的結果。
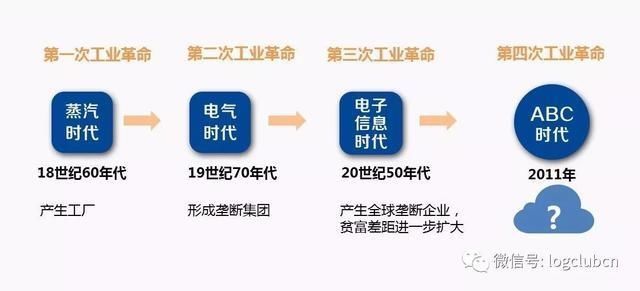
毫無疑問,基于當前計算機技術能力的發(fā)展這兩者必然會改變未來,尤其是物流行業(yè)這樣一個操作密集型的行業(yè)。當下物流企業(yè)的高層技術管理人員,對這兩者賦能物流企業(yè)寄予厚望。
從本文開頭任職要求可以看出,這個大型物流企業(yè)在以處理大數據要求招聘數據開發(fā)工程師,那么作為新興部門或企業(yè),是否有必要招此類開發(fā)工程師?是否能接地氣,實用性高不高?
數據處理分析就如同一個廚師將各種食材,進行加工處理,得出一道美味的菜肴。所以數據原材料是數據分析師處理的“食材”,數據處理加工的工具如同加工過程中的烹飪工具,處理結果就是最后的“菜肴”。那么如果烹飪工具很高級,廚師技術很高,但是食材缺乏,怎么能做出美味的“菜肴”?
食材分多種,有基礎食材,有清洗后食材,有刀切完成的食材。下圖表示數據分析與基礎工作流程的嵌套邏輯:

上圖還可以用另外一種實際操作場景予以表述:
1、底層表示最基礎的數據采集層,比如商品出售時掃描商品碼是第一個采集數據行為,然后客人用相應的支付寶賬號進行付款,這是第二個需要采集的數據。最基礎的數據采集,表示在第一現場做的行為的數據記錄,這是我們進行數據分析的前提,這期間如果數據的采集量極其大,那么需要用處理性能高的服務器與工具,此時Spark就能發(fā)揮作用。這個底層系統(tǒng)我們一般稱為基礎業(yè)務系統(tǒng);
2、中間第二,第三層是數據分析加數據采集,比如根據商品流動排名分析(這是第一層數據分析的結果),店主購買排名第一的銷售商品,這是第二層的采集行為,其建立在第一層分析基礎上,以分析結果作為第二層數據采集的起點,向后延伸采集更多的數據,這兩層管理系統(tǒng),我們稱為業(yè)務管理系統(tǒng)。
3、最上面一層是數據結果層,比如該商品根據流出與采購下達,預計某個具體日期的庫存量,并作出相應的補貨或促銷推薦。這是最后展示及可被系統(tǒng)自動推薦用于決策的數據。整個過程完成了所有數據處理及人工智能。一般這個層次是最后的數據呈現層,一般使用BI工具進行數據分發(fā)。
上面這個例子說明數據分析與流程嵌套之間的關系:沒有基礎采集準備就沒有可分析的材料,沒有數據分析的結果作為二層管理流程的起點就沒有后續(xù)的采集節(jié)點。數據分析與流程相輔相成,這是為什么我在上一篇《聯(lián)盟成網之“坑”》中說到依附于體系的流程探索如繡花,需要試錯與積累,逐層細化,從而讓系統(tǒng)流程覆蓋率逐漸提高,數據協(xié)調能力提升,管理能力才能穩(wěn)健的原因。
可以想象,巧婦在做無米之炊的時候,她只有兩個選擇:1.去自己找米;2.不做飯了。對數據開發(fā)工程師來說就是:1.我去填基礎數據采集不全的坑;2.我離職不干了。
填坑的場景在物流網絡中如下:你想讓數據開發(fā)做分撥更優(yōu)的人員模型配置,現在貨物已經做了條碼標記,流轉過程中可以進行掃描記錄,但是場地分揀貨裝卸操作過程中,庫位未標記,人員標記也未記錄到系統(tǒng)中,根本無法知道現有人員的效能。數據開發(fā)工程師等著業(yè)務部門去布設流程開發(fā)基礎業(yè)務操作系統(tǒng)太慢了,自己直接沖進去做基礎操作系統(tǒng)了。
上述情形說明一個優(yōu)秀的數據分析工程師在條件完備的公司下可以很好地利用他的能力為管理者提供更好的決策依據。在一個條件尚不成熟的企業(yè),寧可潛心做管理建設與體系打造,不要過早引入大數據分析工程師,造成企業(yè)成本浪費與優(yōu)秀人才信任透支。
電商類行業(yè)以互聯(lián)網為基礎發(fā)展而來,本身是在線化產物,大數據AI的應用往往集中在此,這也是市面上近期大數據分析工程師這么火熱的原因。物流行業(yè)本質上仍是傳統(tǒng)行業(yè),互聯(lián)網信息技術只是幫助物流提高效率,國內物流任何一家企業(yè)說他在線化已經完全實現為時尚早,所以國內物流且應該更多反觀自己內部的信息化進度,先少關注一點高精尖技術。
AI核心本質是人工建立的算法模型,讓計算機語言將人腦中的算法模型予以表現。市面上經常會說一些數據分析的方法論:回歸分析、聚類分析、神經網絡方法等。在實際模型建設中,這些方法論能幫助實際應用模型的作用微乎其微。更多的是從實際場景與需求出發(fā),把專業(yè)人士多年的經驗從大腦中進行提取,歸納,抽象。人腦中的經驗與精華才是人工智能的“本”,代碼與軟件實現是“末”。
此文系作者個人觀點,不代表物流沙龍立場
-END-


美國對中國商品加征10%關稅,對跨境電商的巨大沖擊
801 閱讀
白犀牛副總裁王瀚基:無人配送帶來了哪些機遇與挑戰(zhàn)?
645 閱讀
SCOR模型:數字化時代供應鏈管理的航海圖
661 閱讀快遞人2025愿望清單:漲派費、少罰款、交社保......
641 閱讀暖心護航春節(jié)返程,順豐確保每一份滿滿當當的心意與牽掛新鮮抵達!
434 閱讀1月27日-2月2日全國物流保通保暢運行情況
447 閱讀京東物流北京區(qū)25年331大件DC承運商招標
446 閱讀春節(jié)假期全國攬投快遞包裹超19億件
425 閱讀2025年1月20日-1月26日全國物流保通保暢運行情況
380 閱讀
微信-客服二維碼-1_7FYvfo9xbJql.png?x-oss-process=image/quality,Q_80)






粵公網安備 44030402005698號