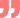

我們可以通過一個比喻來解釋什么是行為風險識別:自動駕駛的機器大腦在參加一場考試,他遇到一道難題,在兩個答案之間猶豫不決。盡管這道難題他不會做,但我們可以通過許多方式得知他“拿不準”這件事本身,例如題目描述的場景復雜或者之前不熟悉,并進一步針對這道題目請求“人類教練”的幫助。
我們人類在開車的時候,會由眼睛和耳朵等“傳感器”完成對環境信息的探測和感知,然后這些信息傳入我們的大腦,大腦經過所有的處理之后,發出直接的動作指令給“控制器“——我們的手和腳。
對于人類大腦的工作過程,我們還所知有限。而在當前的自動駕駛技術中,有一種嘗試是“端到端”技術,也就是完全模擬我們的大腦,試圖直接將傳感器獲得的環境信息輸入深度神經網絡,直接輸出對車輛的控制信號。
這類方法存在一個最大的問題就是深度神經網絡缺乏可解釋性。當遇到未知的場景時,我們無法保障網絡輸出結果的安全性。因此,當前絕大部分自動駕駛企業還是采用分層和解耦的思路,來解決自動駕駛決策的問題。
在這種思路下,自動駕駛的大腦工作由決策規劃模塊來完成(更多詳細內容可參考之前的技術文章):

圖1. 自動駕駛系統中的決策規劃模塊分層結構
如圖1所示,典型的決策規劃模塊可以分為三個層次。其中,全局路徑規劃(Route Planning)在接收到一個給定的行駛目的地之后,結合地圖信息,生成一條全局的路徑,作為為后續具體路徑規劃的參考;行為決策層(Behavioral Layer)在接收到全局路徑后,結合從感知模塊得到的環境信息(包括其他車輛與行人,障礙物,以及道路上的交通規則信息),以及從預測模塊得到的障礙物未來可能行駛軌跡信息,作出具體的行為決策(例如選擇變道超車還是跟隨);最后,運動規劃(Motion Planning)層根據具體的行為決策,規劃生成一條滿足特定約束條件(例如車輛本身的動力學約束、避免碰撞、乘客舒適性等)的軌跡,該軌跡作為控制模塊的輸入決定車輛最終行駛路徑。
通過上面的介紹我們已經知道,機器大腦通過分層的方法來降低問題難度。在目前的技術發展階段,全局路徑規劃和運動規劃這兩個部分的方案已經相對比較成熟。這一方面也是由于這兩層的任務目標十分明確(我們的行駛目的地是確定的;運動規劃需要滿足的約束條件也是確定的)。
而在行為決策層,我們需要面對的則是一系列不確定性的輸入信息。這種不確定性的來源主要有兩大部分:
一部分來自環境,因為我們的物理世界本身就是在不斷變化的,環境中其他交通參與者未來的行為我們無法明確得知(預測模塊的任務就是降低這一類不確定性)
另一部分來自傳感器在采集和處理環境信息的時候(將物理世界在數字世界中建模),不可避免地需要進行采樣等離散化處理,這樣就導致真實物理世界的連續信息有一部分損失,同時也會產生空間上的誤差和時間上的延遲。
與之相對的是,行為決策層的輸出卻必須是確定性的結果,具體來說,這些輸出通常包括:
綜合決策(主車的綜合決策行為,如換道意圖和借道意圖)
個體決策(主車對單個障礙物做出的決策,如繞行和減速避讓)
用嚴格一些的語言來說,下游運動規劃層需要生成具體的行駛軌跡,在數學上這是一個非凸優化問題,難以直接求解,因此行為決策需要將運動規劃的解空間進行限定,保證運動規劃模塊的求解高效性和穩定性。
在處理這些輸入不確定性,并輸出確定性決策的過程中。我們需要考慮的目標是多樣化的,不僅僅包括安全性,還要考慮交通規則、決策穩定性,車輛模型,甚至還要求無人車的行為需要符合人類駕駛習慣(環境中存在大量與人類參與者的交互)。
我們需要將這些多目標轉換為機器容易理解和處理的方式,具體手段包括:
約束目標:將碰撞避免、交通規則等目標轉換為不可以違反的邊界條件。
優化目標:對一些軟性的目標(通行效率、舒適性等)設置不同權重的損失懲罰函數。
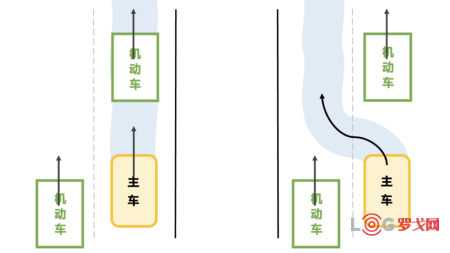
由于輸入信息的不確定性,我們的機器大腦在實際中常常面臨“兩難”的局面。例如下圖這樣十分常見的一種場景,選擇減速跟車還是換道超車。前者會影響通行效率,而后者則可能帶來更高的風險(旁邊車道來車)。

圖2. 常見的一種行為決策場景:減速or變道
而實際的場景更為復雜多變,并且一定會出現長尾場景,每一種行為決策的選擇都不可能完全避免未來的風險,決策輸出的多目標求解過程無法保證每次都得到最低風險的結果。因此,我們需要在行為決策層增加一種以安全性為單目標的算法模型,希望能夠對可能發生的風險進行提前的識別,當安全性不滿足要求時采用人工接管或保守策略。
讀者可能提出的一個問題是:如果能夠建立這樣的風險識別模型,那不就可以作出最安全的行為決策了嗎?這個問題的答案其實就是在“知道正確答案”和“知道不會做”二者之間其實是存在一個gap的。在預期功能安全國際標準(ISO/PAS 21448)中,場景(scenarios)被劃分為如下圖所示的4個區間,分別為(1)已知-安全、(2)已知-不安全、(3)未知-不安全和(4)未知-安全。最終的目標是盡可能縮小位于區間(2)和(3)中的場景(scenarios)比例,即將確保場景(scenarios)控制在安全的區間。而行為風險識別希望達到的目的就是將區間(3)中的場景首先轉化為區間(2),即“know unknowns”。接下來,隨著行為決策本身算法能力的不斷提升(越來越見多識廣),才能夠將更多的區間(2)場景轉化為區間(1)。

圖3. 國際標準ISO/PAS 21448中對場景(scenarios)的分類
無人車行為決策模塊面對的是高不確定性的動態場景。在當前技術階段,存在算法能力的覆蓋邊界。在邊界上存在的長尾問題是最難解決的一類問題,同時也是最危險的場景。在我們的自動駕駛算法不斷進步,不斷擴大能力邊界的同時,我們也希望通過對行為決策模塊各種指標進行在線監控,同時結合周圍環境信息,希望從這些“蛛絲馬跡”中提前識別出危險場景。然后對算法結果進行反饋,并向人類安全員發出提醒。
行為風險識別的具體算法,以及識別后的處理方式,將在下次技術解析中詳細介紹。


美國對中國商品加征10%關稅,對跨境電商的巨大沖擊
927 閱讀
白犀牛副總裁王瀚基:無人配送帶來了哪些機遇與挑戰?
708 閱讀
SCOR模型:數字化時代供應鏈管理的航海圖
752 閱讀快遞人2025愿望清單:漲派費、少罰款、交社保......
697 閱讀京東物流北京區25年331大件DC承運商招標
614 閱讀春節假期全國攬投快遞包裹超19億件
488 閱讀暖心護航春節返程,順豐確保每一份滿滿當當的心意與牽掛新鮮抵達!
455 閱讀1月27日-2月2日全國物流保通保暢運行情況
482 閱讀2025年1月20日-1月26日全國物流保通保暢運行情況
408 閱讀“朝令夕改”!美國郵政恢復接收中國包裹
184 閱讀







粵公網安備 44030402005698號


 [羅戈導讀]無人車行為決策模塊面對的是高不確定性的動態場景。
[羅戈導讀]無人車行為決策模塊面對的是高不確定性的動態場景。